近期,AI领域迎来了一场重大变革,DeepSeek凭借其卓越的性能、成本控制以及易用性,成功吸引了腾讯、百度等互联网巨头的青睐。两大互联网巨头先后将DeepSeek接入其生态系统,使其在微信搜索和百度搜索两大超级入口中占据了席之地,影响力瞬间覆盖数亿用户。
这一举动背后,透露出传统互联网巨头在AI时代下的无奈与被动。尽管自研模型一直是巨头们的首选,但DeepSeek在多方面展现出的优势,让巨头们不得不重新审视自己的战略。接入DeepSeek,成为了它们维持竞争力的权宜之计。
同时,巨头们也在积极寻求通过生态整合和组织变革,将DeepSeek转化为自身的竞争优势。这一战略选择,不仅是对现有生态的快速整合,更是对先进技术的一次深度拥抱,旨在巩固和提升自己的市场地位。
自生成式AI诞生以来,AI大模型在功能集成方面一直难以做到深度场景化应用。这主要是因为,要实现真正的场景化AI,需要打通大量的数据孤岛和应用场景,而这些数据和场景往往被不同的互联网平台所分割。据IDC报告显示,中国互联网行业的数据存储量中,73%集中在腾讯、阿里、字节等TOP10平台,但跨平台数据调用的成功率却不足5%。

以搜索为例,现有的头部模型虽然具备联网搜索功能,但所能抓取的大都是公域信息,对于私域内容,如公众号平台的数据,则难以触及。只有腾讯自家的元宝模型能够做到这一点。这种私有流量池的存在,使得大量用户的阅读兴趣、浏览记录等数据被牢牢掌控。
百度APP作为全球最大的中文搜索引擎,拥有7亿用户,集成了搜索、地图、贴吧、网盘、文库、知道、健康等20多项功能。用户在搜索框键入文字时,需求可能不仅仅是信息查阅,而是多种功能和场景的交互结果。这种跨场景的连接能力,是第三方AI难以实现的。
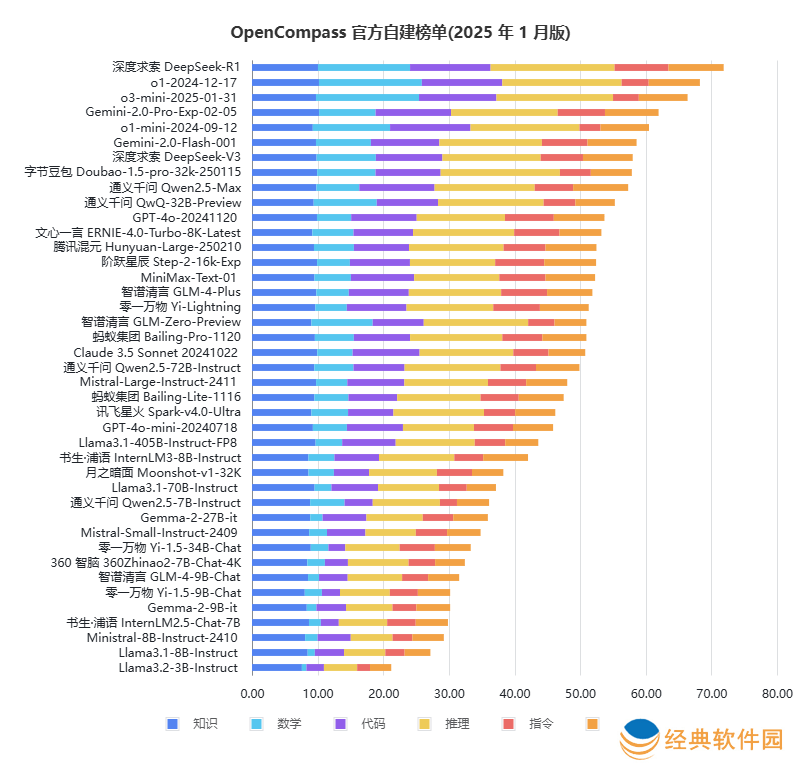
然而,掌握着庞大数据和应用场景的巨头们,其AI模型的表现却往往不尽如人意。司南大模型榜单显示,腾讯的文心一言与混元模型明显落后于DeepSeek-R1。这形成了传统互联网巨头“有入口但模型拉胯”,AI企业“模型强却无入口”的割裂局面。
DeepSeek-R1的问世,彻底改变了这一局面。凭借其强大的性能和低廉的成本,DeepSeek的“生态朋友圈”迅速扩大,覆盖了智能硬件、汽车、传媒、互联网、半导体等多个行业。各大巨头也意识到,未来的AI领域,很可能将由一两个在性能和成本上兼具优势的“超级模型”主导。
尽管接入了DeepSeek,但腾讯、百度等巨头并未放弃自研模型。腾讯元宝在接入DeepSeek后不久,就更新了APP,上线了混元的推理模型T1。巨头们试图在外部技术和自主可控之间寻求平衡,避免因过度依赖第三方模型而失去技术制高点。
然而,DeepSeek-R1的开源并不意味着竞争对手可以轻易复现其性能。其MoE架构和“多头潜在注意力”机制需要大量的测试数据和强化学习优化的实战经验作为支撑。这背后凝结的是高深的工程学经验,使得DeepSeek-R1成为一种易学难精的技术。
DeepSeek之所以能吸引一批具有海外经验的顶尖AI人才加入,得益于其扁平、灵活的组织架构。这种组织架构上的优势,是百度、腾讯等大厂目前所不具备的。而百度在发布2024年全年财报后股价的下跌,也反映出市场对这家老牌搜索巨头在AI转型上的疑虑。
在未来的互联网生态中,“平台为主”还是“AI优先”的趋势尚不明朗。但从当前的中国AI竞争格局来看,传统互联网巨头的“数据+场景”护城河难以撼动。未来的破局点,或许在于“数据流动性×场景适配性×商业可行性”的多元平衡。